Triangle rasterization in practice
This post is part of a series – go here for the index.
Welcome back! The previous post gave us a lot of theoretical groundwork on triangles. This time, let’s turn it into a working triangle rasterizer. Again, no profiling or optimization this time, but there will be code, and it should get us set up to talk actual rasterizer optimizations in the next post. But before we start optimizing, let’s first try to write the simplest rasterizer that we possibly can, using the primitives we saw in the last part.
The basic rasterizer
As we saw last time, we can calculate edge functions (which produce barycentric coordinates) as a 2×2 determinant. And we also saw last time that we can check if a point is inside, on the edge or outside a triangle simply by looking at the signs of the three edge functions at that point. Our rasterizer is going to work in integer coordinates, so let’s assume for now that our triangle vertex positions and point coordinates are given as integers too. The orientation test that computes the 2×2 determinant looks like this in code:
struct Point2D {
int x, y;
};
int orient2d(const Point2D& a, const Point2D& b, const Point2D& c)
{
return (b.x-a.x)*(c.y-a.y) - (b.y-a.y)*(c.x-a.x);
}
Now, all we have to do to rasterize our triangle is to loop over candidate pixels and check whether they’re inside or not. We could do it brute-force and loop over all screen pixels, but let’s try to not be completely brain-dead about this: we do know that all pixels inside the triangle are also going to be inside an axis-aligned bounding box around the triangle. And axis-aligned bounding boxes are both easy to compute and trivial to traverse. This gives:
void drawTri(const Point2D& v0, const Point2D& v1, const Point2D& v2)
{
// Compute triangle bounding box
int minX = min3(v0.x, v1.x, v2.x);
int minY = min3(v0.y, v1.y, v2.y);
int maxX = max3(v0.x, v1.x, v2.x);
int maxY = max3(v0.y, v1.y, v2.y);
// Clip against screen bounds
minX = max(minX, 0);
minY = max(minY, 0);
maxX = min(maxX, screenWidth - 1);
maxY = min(maxY, screenHeight - 1);
// Rasterize
Point2D p;
for (p.y = minY; p.y <= maxY; p.y++) {
for (p.x = minX; p.x <= maxX; p.x++) {
// Determine barycentric coordinates
int w0 = orient2d(v1, v2, p);
int w1 = orient2d(v2, v0, p);
int w2 = orient2d(v0, v1, p);
// If p is on or inside all edges, render pixel.
if (w0 >= 0 && w1 >= 0 && w2 >= 0)
renderPixel(p, w0, w1, w2);
}
}
}
And that’s it. That’s a fully functional triangle rasterizer. In theory anyway – you need to write the min / max and renderPixel functions yourself, and I didn’t actually test this code, but you get the idea. It even does 2D clipping. Now, don’t get me wrong. I don’t recommend that you use this code as-is anywhere, for reasons I will explain below. But I wanted you to see this, because this is the actual heart of the algorithm. In any implementation of it that you’re ever going to see in practice, the wonderful underlying simplicity of it is going to be obscured by the various wrinkles introduced by various features and optimizations. That’s fine – all these additions are worth their price. But they are, in a sense, implementation details. Hell, even limiting the traversal to a bounding box is just an optimization, if a simple and important one. The point I’m trying to make here: This is not, at heart, a hard problem that requires a complex solution. It’s a fundamentally simple problem that can be solved much more efficiently if we apply some smarts – an important distinction.
Issues with this approach
All that said, let’s list some problems with this initial implementation:
- Integer overflows. What if some of the computations overflow? This might be an actual problem or it might not, but at the very least we need to look into it.
- Sub-pixel precision. This code doesn’t have any.
- Fill rules. Graphics APIs specify a set of tie-breaking rules to make sure that when two non-overlapping triangles share an edge, every pixel (or sample) covered by these two triangles is lit once and only once. GPUs and software rasterizers need to strictly abide by these rules to avoid visual artifacts.
- Speed. While the code as given above sure is nice and short, it really isn’t particularly efficient. There’s a lot we can do make it faster, and we’ll get there in a bit, but of course this will make things more complicated.
I’m going to address each of these in turn.
Integer overflows
Since all the computations happen in orient2d, that’s the only expression we actually have to look at:
(b.x-a.x)*(c.y-a.y) - (b.y-a.y)*(c.x-a.x)
Luckily, it’s pretty very symmetric, so there’s not many different sub-expressions we have to look at: Say we start with p-bit signed integer coordinates. That means the individual coordinates are in [-2p-1,2p-1-1]. By subtracting the upper bound from the lower bound (and vice versa), we can determine the bounds for the difference of the two coordinates:

And the same applies for the other three coordinate differences we compute. Next, we compute a product of two such values. Easy enough:
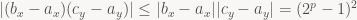
Again, the same applies to the other product. Finally, we compute the difference between the two products, which doubles our bound on the absolute value:
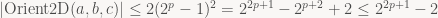
since p is always nonnegative. Accounting for the sign bit, that means the result of Orient2D fits inside a (2p+2)-bit signed integer. Since we want the results to fit inside a 32-bit integer, that means we need 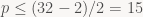
Incidentally, this is shows how a typical implementation guard band clipping works: the rasterizer performs computations using some set bit width, which determines the range of coordinates that the rasterizer accepts. X/Y-clipping only needs to be done when a triangle doesn’t fall entirely within that region, which is very rare with common viewport sizes. Note that there is no need for rasterizer coordinates to agree with render-target coordinates, and if you want to maximize the utility of your guard band region, your best bet is to translate the rasterizer coordinate system such that the center (instead of the top-left or bottom-right corner) of your viewport is near (0,0). Otherwise large viewports might have a much bigger guard band on the left side than they do on the right side (and similar in the vertical direction), which is undesirable.
Anyway. Integer overflows: Not a big deal, at least in our current setup with all-integer coordinates. We do need to check for (and possibly clip) huge triangles, but they’re rare in practice, so we still get away with no clipping most of the time.
Sub-pixel precision
For this point and the next, I’m only going to give a high-level overview, since we’re not actually going to use it for our target application.
Snapping vertex coordinates to pixels is actually quite crappy in terms of quality. It’s okay for a static view of a static scene, but if either the camera or one of the visible objects moves very slowly, it’s quite noticeable that the triangles only move in discrete steps once one of the vertices has moved from one pixel to the next after rounding the coordinates to integer. It looks as if the triangle is “wobbly”, especially so if there’s a texture on it.
Now, for the application we’re concerned with in this series, we’re only going to render a depth buffer, and the user is never gonna see it directly. So we can live with artifacts that are merely visually distracting, and needn’t bother with sub-pixel correction. This still means that the triangles we software-rasterize aren’t going to match up exactly with what the hardware rasterizer does, but in practice, if we mistakenly occlusion-cull an object even though some of its pixel are just about visible due to sub-pixel coordinate differences, it’s not a big deal. And neither is not culling an object because of a few pixels that are actually invisible. As one of my CS professors once pointed out, there are reasonable error bounds for everything, and for occlusion culling, “a handful of pixels give or take” is a reasonable error bound, at least if they’re not clustered together!
But suppose that you want to actually render something user-visible, in which case you absolutely do need sub-pixel precision. You want at least 4 extra bits in each coordinate (i.e. coordinates are specified in 1/16ths of a pixel), and at this point the standard in DX11-compliant GPUs in 8 bits of sub-pixel precision (coordinates in 1/256ths of a pixel). Let’s assume 8 bits of sub-pixel precision for now. The trivial way to get this is to multiply everything by 256: our (still integer) coordinates are now in 1/256ths of a pixel, but we still only perform one sample each pixel. Easy enough: (just sketching the updated main loop here)
static const int subStep = 256;
static const int subMask = subStep - 1;
// Round start position up to next integer multiple
// (we sample at integer pixel positions, so if our
// min is not an integer coordinate, that pixel won't
// be hit)
minX = (minX + subMask) & ~subMask;
minY = (minY + subMask) & ~subMask;
for (p.y = minY; p.y <= maxY; p.y += subStep) {
for (p.x = minX; p.x <= maxX; p.x += subStep) {
// Determine barycentric coordinates
int w0 = orient2d(v1, v2, p);
int w1 = orient2d(v2, v0, p);
int w2 = orient2d(v0, v1, p);
// If p is on or inside all edges, render pixel.
if (w0 >= 0 && w1 >= 0 && w2 >= 0)
renderPixel(p, w0, w1, w2);
}
}
Simple enough, and it works just fine. Well, in theory it does, anyway – this code fragment is just as untested as the previous one, so be careful :). By the way, this seems like a good place to note that if you’re writing a software rasterizer, this is likely not what you want: This code samples triangle coverage at integer coordinates. This is simpler if you’re writing a rasterizer without sub-pixel correction (as we will do, which is why I set up coordinates this way), and it also happens to match with D3D9 rasterization conventions, but it disagrees with OpenGL and D3D10+ rasterization rules, which turn out to be saner in several important ways for a full-blown renderer. So consider yourselves warned.
Anyway, as said, this works, but it has a problem: doing the computation like this costs us a lot of bits. Our accepted coordinate range when working with 32-bit integers is still [-16384,16383], but now that’s in sub-pixel steps and boils down to approximately [-64,63.996] pixels. That’s tiny – even if we center the viewport perfectly, we can’t squeeze more than 128 pixels along each axis out of it this way. One way out is to decrease the level of sub-pixel precision: at 4 bits, we can just about fit a 2048×2048 pixel render target inside our coordinate space, which isn’t exactly comfortable but workable.
But there’s a better way. I’m not gonna go into details here because we’re already on a tangent and the details, though not hard, are fairly subtle. I might turn it into a separate post at some point. But the key realization is that we’re still taking steps of one pixel at a time: all the p’s we pass into orient2d are an integral number of pixel samples apart. This, together with the incremental evaluation we’re gonna see soon, means that we only have to do a full-precision calculation once per triangle. All the pixel-stepping code always advances in units of integral pixels, which means the sub-pixel size enters the computation only once, not squared. Which in turn means we can actually cover the 2048×2048 render target with 8 bits of subpixel accuracy, or 8192×8192 pixels with 4 bits of subpixel resolution. You can squeeze that some more if you traverse the triangle in 2×2 pixel blocks and not actual pixels, as our triangle rasterizer and any OpenGL/D3D-style rasterizer will do, but again, I digress.
Fill rules
The goal of fill rules, as briefly explained earlier, is to make sure that when two non-overlapping triangles share an edge and you render both of them, each pixel gets processed only once. Now, if you look at an actual description (this one is for D3D10 and up), it might seem like they’re really tricky to implement and require comparing edges to other edges, but luckily it all turns out to be fairly simple to do, although I’ll need a bit of space to explain it.
Remember that our core rasterizer only deals with triangles in one winding order – let’s say counter-clockwise, as we’ve been using last time. Now let’s look at the rules from the article I just pointed you to:
A top edge, is an edge that is exactly horizontal and is above the other edges.
A left edge, is an edge that is not exactly horizontal and is on the left side of the triangle.

The “exactly horizontal” part is easy enough to find out (just check if the y-coordinates are different), but the second half of these definitions looks troublesome. Luckily, it turns out to be fairly easy. Let’s do top first: What does “above the other edges” mean, really? An edge connects two points. The edge that’s “above the other edges” connects the two highest vertices; the third vertex is below them. In our example triangle, that edge is v1v2 (ignore that it’s not horizontal for now, it’s still the edge that’s above the others). Now I claim that edge must be one that is going towards the left. Suppose it was going to the right instead – then v0 would be in its right (negative) half-space, meaning the triangle is wound clockwise, contradicting our initial assertion that it’s counter-clockwise! And by the same argument, any horizontal edge that goes to the right must be a bottom edge, or again we’d have a clockwise triangle. Which gives us our first updated rule:
In a counter-clockwise triangle, a top edge is an edge that is exactly horizontal and goes towards the left, i.e. its end point is left of its start point.
That’s really easy to figure out – just a sign test on the edge vectors. And again using the same kind of argument as before (consider the edge v2v0), we can see that any “left” edge must be one that’s going down, and that any edge that is going up is in fact a right edge. Which gives us the second updated rule:
In a counter-clockwise triangle, a left edge is an edge that goes down, i.e. its end point is strictly below its start point.
Note we can drop the “not horizontal” part entirely: any edge that goes down by our definition can’t be horizontal to begin with. So this is just one sign test, even easier than testing for a top edge!
And now that we know how to identify which edge is which, what do we do with that information? Again, quoting from the D3D10 rules:
Any pixel center which falls inside a triangle is drawn; a pixel is assumed to be inside if it passes the top-left rule. The top-left rule is that a pixel center is defined to lie inside of a triangle if it lies on the top edge or the left edge of a triangle.
To paraphrase: if our sample point actually falls inside the triangle (not on an edge), we draw it no matter what. It if happens to fall on an edge, we draw it if and only if that edge happens to be a top or a left edge.
Now, our current rasterizer code:
int w0 = orient2d(v1, v2, p);
int w1 = orient2d(v2, v0, p);
int w2 = orient2d(v0, v1, p);
// If p is on or inside all edges, render pixel.
if (w0 >= 0 && w1 >= 0 && w2 >= 0)
renderPixel(p, w0, w1, w2);
Draws all points that fall on edges, no matter which kind – all the tests are for greater-or-equals to zero. That’s okay for edge functions corresponding to top or left edges, but for the other edges we really want to be testing for a proper “greater than zero” instead. We could have multiple versions of the rasterizer, one for each possible combination of “edge 0/1/2 is (not) top-left”, but that’s too horrible to contemplate. Instead, we’re going to use the fact that for integers, x > 0 and x >= 1 mean the same thing. Which means we can leave the tests as they are by first computing a per-edge offset once:
int bias0 = isTopLeft(v1, v2) ? 0 : -1; int bias1 = isTopLeft(v2, v0) ? 0 : -1; int bias2 = isTopLeft(v0, v1) ? 0 : -1;
and then changing our edge function computation slightly:
int w0 = orient2d(v1, v2, p) + bias0;
int w1 = orient2d(v2, v0, p) + bias1;
int w2 = orient2d(v0, v1, p) + bias2;
// If p is on or inside all edges, render pixel.
if (w0 >= 0 && w1 >= 0 && w2 >= 0)
renderPixel(p, w0, w1, w2);
Full disclosure: this changes the barycentric coordinates we pass to renderPixel slightly (as does the subpixel-precision squeezing we did earlier!). If you’re not using sub-pixel correction, this can be quite a big error, and you want to correct for it. With sub-pixel correction, you might decide that being off-by-1 on interpolated quantities is no big deal (remember that the edge functions are in area units, so “1” is a 1-subpixel-by-1-subpixel square, which is fairly small). Either way, the bias values are computed once per triangle, and you can usually do the correction once per triangle too, so it’s no extra per-pixel overhead. Right now, we pay some per-pixel cost to apply the biases too, but it turns out that will go away once we start optimizing it. And by the way, if you go back to the “integer overflow” section, you’ll notice we had a bit of slack on the precision requirements; the “bias” terms will not cause us to need any extra bits. So it really does all work out, and we can get proper fill rule handling in our rasterizer.
Which reminds me: This is the part where I tell you that the depth buffer rasterizer we’re going to look at doesn’t bother with implementing a consistent fill rule. It has the same “fill everything inside or on the edge” behavior as our initial code does. That might be an oversight, or it might be an intentional decision to make the rasterizer slightly conservative, which would make sense given the application. I’m not sure, and I decided not to mess with it. But I figured that since I was writing a post on rasterization, it would be a sin not to describe how to do this properly, especially since a coherent explanation of how exactly it’s done is quite hard to find on the net.
All that’s fine and good, but now how do we make it fast?
Well, that’s a big question, and – much as I hate to tell you – one that I will try to answer in the next post. We’ll also end this brief detour into software rasterization generalities and get back to the Software Occlusion Culling demo that started this series.
So what’s the point of this and the previous post? Well, first off, this is still my blog, and I just felt like writing about it. :) And just as importantly, I’m going to spend at least two posts poking around in the guts of a rasterizer, and none of the changes I’m going to describe will make any sense to you without this background information. Low-hanging fruit are all nice and good, but sometimes you actually have to work for it, and this is one of those times. Besides, while optimizing code is fun, correctness isn’t optional. Fast code that doesn’t do what it’s supposed to is no good to anyone. So I’m trying to get it right before we make it fast. I can promise you it will be worth your while, though, and I’ll try to finish and upload the next post quickly. Until then, take care!

Really enjoying these posts!
The if (w0 >= 0 && w1 >= 0 && w2 >= 0) statement will break your pipeline, it’s slow and that’s why this approach was never used on old hardware. In fact, this still hold true. the best way is to rasterize your lines and then draw strips. THIS is the way that’s nice to your execution pipeline.
While that might be true, fabien shows in later articles how to make the code branchless. Old CPUs are old for a reason, its much faster to take this aproach and use vector instructions to process multiple pixels at once and use masked writes in place of the conditional. With this algorythm its trivial to parallelize over multiple cores too. These things would be harder using the traditional scanline algorythm you suggest.
Doesn’t this approach ignore perspective-correct interpolation? Is that safe to do in the context of occlusion culling? If you did want to do perspective-correct interpolation, would you linearly interpolate the homogeneous z and 1/w and multiply them? Would those values have to be interpolated in floating point?
Thanks
–Butch
It does not. Throughout all my posts (not just in this series), I am very careful to distinguish between z and w (vertex position components, which are linear in clip space, pre-perspective divide) and Z=z/w, which is the value written into the Z-buffer and linear in screen space, post-perspective divide. Note that Z=z/w is one of the two values you would interpolate linearly in screen space to do a perspective-correct interpolation of the view-space z (if that’s what you wanted) – the other would be 1/w.
This, in short, is why GPUs (and software rasterizers!) prefer Z-buffers: they’re the cheapest way to get depth interpolation and testing that is perspective-correct. The equivalent that actually uses view-space z or w is normally called a W-buffer; it does require full perspective interpolation and is therefore much more expensive to rasterize depth buffers with.
The standard perspective matrix is set up so that Z=0 (or -1 for the OpenGL convention) at the near clip plane, and Z=1 at the far clip plane. Note that Z (unlike clip-space z or w!) has uneven resolution – since it’s a function of 1/w, most of its value range is taken up by points close to w=0. This is why Z-buffers have better depth resolution around the near plane.
Thanks, I had convinced myself that the Z buffer couldn’t work with interpolated Z = z/w, but having worked through my supposed counterexample, I see how it does work now.
I am curious how 32 bit integers can handle 2048*2048 pixel render target with 8 bits sub-pixel precision. Waiting for your post about that :D
There’s no separate post for that, I explained it in this one!
During triangle setup, you calculate the edge functions at some position on the screen. The “integer overflows” section goes through exactly what the precision requirements are for that. Say we have a 2048×2048 render target. For the purposes of rasterization, we want to shift the origin of our coordinate space so the pixel coordinates are not [0,2047] but [-1024,1023] instead (I already mention that trick in the article).
By the notation in the article, that’s a 11-bit signed number (p=11), and calculating the determinants directly will require (2p+2) = 24 bits. This is still without subpixel precision – with me so far?
Okay. Now for subpixel, you add another 8 bits to the coordinates, giving you p=19, so calculating the determinants requires (2p+2) = 40 bits, which is indeed more than 32. So how do we get rid of the extra 8 bits? As I say in the article: “All the pixel-stepping code always advances in units of integral pixels” (see the follow-up post one later in the series for what I mean by “pixel-stepping”).
The point is that we are evaluating the edge functions on a pixel grid. Without subpixel precision, we’re gonna be evaluating F(x0, y0), F(x0+1, y0), F(x0+2, y0), later F(x0, y0+1) and so forth. With 8-bit subpixel precision, our coordinates are in sub-pixels but we’re still stepping in pixel increments, so we’re looking at first F(x0, y0), then F(x0+256, y0), F(x0+512, y0) and so forth. “Optimizing the basic rasterizer” shows that F(x,y) is just an affine function of x and y: F(x,y) = A*x + B*y + C, and so F(x+dx*256, y+dy*256) – F(x,y) = (dx*256)*A + (dy*256)*B = (dx*A + dy*B) * 256. If we’re stepping in pixel increments, that means F only changes by multiples of 256. In other words, the lowest 8 bits of F are always the same at every pixel – they’re just the lowest 8 bits of C. And since they’re constant, they can’t ever generate a carry that would affect the higher bits of F – the sign bit in particular.
Which means there’s no reason to carry them around (pun intended) in the first place. We need to do the triangle setup in 40-bit integer (which in practice means 64-bit for software implementations), but at the end of setup we can just right-shift by 8 and get rid of the extra bits without changing the results.
Note that this works in general. This is not a hack, and it works just fine with arbitrary pixel coverage sampling positions and MSAA. Suppose that we’re not sampling triangle coverage at integer pixel coordinates (as the rasterizer I’m describing in this series does), but instead use the “integer + 0.5” convention used by both OpenGL and Direct3D. The + 0.5 part figures into the initial triangle setup (which now sees slightly different coordinates) but the sampling positions are still on a grid with 1-pixel spacing which is all we need to make this work.
Similarly with multisampling. The default multisampling patterns are not a regular grid layout as people seem to intuitively expect, because gridded sampling positions perform poorly with near-horizontal or near-vertical edges (which are quite common); instead they use low-discrepancy sampling patterns intended to provide good results for all orientations. See here for an example of how the patterns actually look.
Anyway, the crucial trick again is that while the placement of samples within the pixel is somewhat random, it repeats for every pixel. So again, if I were to plot say the location of MSAA sample 3 for the entire screen, I would still get a 1-pixel spaced grid. To render with N-times MSAA, during triangle setup, you have to calculate the full-subpixel-precision values of the initial edge equations for each of the N samples. But after setup you can still shift out the extra bits because they’re not going to influence the results any further.
And again, there’s nothing holy about pixels here. You can do this at any granularity. For example, GPU rasterizers usually don’t look at individual pixels, but at “quads” of 2×2 pixels. Just as you can “bake in” subpixel positions into the edge equations during triangle setup (and then ignore them for the rest of rasterization), you can also do triangle setup for all samples in a quad not a pixel, step in quad granularity, and bake in the “sub-quad” positions of pixels instead of sub-pixel ones. Or use even larger rasterization stencils if you want. You get the idea.
I’m having nerdgasm after nerdgasm reading your blog! Thank you for that and don’t ever stop pls!
How to treat the shared vertex among more than 2 triangles?? Thanks for the blog post.
What about it? It’s just a vertex.
I mean which triangle will it belong to if it is not to be repeated among the set of triangles say 6 triangles. Or is it taken care of with the top-left edge approach that you have so nicely described.
Yeah, you don’t need to do anything special with shared vertices if you implement a consistent fill rule. It just works.
Talking about the ‘Left edge’. In case of a triangle that is a mirror image of the one in your example will there be 2 left edges as in both cases the edge is going Down. Or is the left edge unique. if yes how to find it. Thanks.
Yes, there can be multiple top/left edges.
Do you have suggestions for quality sources? The nice thing about the math is that you can simply work it out. But it’s a lot harder to verify claims like NVIDIA having been clipless. Likewise for the contents of a D3D spec not just anyone gets to see. You mention D3D11 has mandated 8 subpixel bits in a precise way but I think it’s actually been this way since D3D10. Look at something like this:
https://developer.apple.com/opengl/capabilities/GLInfo_1075.html
There’s been a varying number of SUBPIXEL_BITS until they all jumped to 8 with D3D10. GMA X3100 is the only exception, apparently supporting D3D10 despite lacking more than just subpixel bits. HD Graphics 3000 looks like actual D3D10 hardware and also jumped on the 8 subpixel bits bandwagon.
It’s interesting to bring OpenGL into it. We can all read the spec for one thing. It doesn’t describe rasterization that precisely, however. At all. OpenGL generally only specifies certain properties of the end result like watertight meshes, not the means to get there. The SUBPIXEL_BITS ≥ 4 query is just an afterthought that I’d say can only be taken as an indication of overall precision, seeing how it’s been a single entry in a table in every OpenGL spec ever, with no references to it anywhere.
Technicalities aside, NVIDIA (well, Apple’s NVIDIA driver) did claim 12 subpixel bits before GeForce 8. Whatever the value would mean for a homogeneous rasterizer, a value this large suggests they really put some effort into it. It might well have been homogeneous indeed. Maybe 12 bits is a best case and certain extreme primitives are much less precise. I say homogeneous because I believe a non-homogeneous rasterizer can also be made clipless. It just depends on what exactly you’re asking of it, on whether the possibility is specified to death.
That brings me back to why I want better sources. Does D3D specify it to death? You could specify very precise behavior within a guard band of a certain size but relax requirements for vertices outside that guard band. It would be so cool to know these things. Unfortunately, measuring it is tricky with all modern hardware being pretty much flawless in any case, at least in this regard.
Source for older NV GPUs being clipless: personal communication with then-NV employees. :)
The D3D10 spec mandated at least 8 bits subpixel precision, but you were allowed to have more. D3D11 tightened it to exactly 8 bits. As for the spec not being public, well, there’s nothing I can do about it. Lots of GPUs do have mode flags to toggle more subpixel bits (I know this is true for at least some NV GPUs and recent AMD GPUs) but it doesn’t get exposed via most APIs.
The D3D11+ rasterization specs are tight enough to effectively prescribe which fragment coverage masks get produced for a given set of input vertices provided there is no clipping. (The exact guard band size and behavior of the clipper are not prescribed, so this can cause variation). This is just for the “is the fragment hit, yes or no” bits though. There is much more leeway for attribute interpolation and the like.
Ah, thanks! That’ll have to do.
I’ve noticed attribute interpolation is far from reliable. It’s funny how a game like Minecraft, which doesn’t otherwise ask for much other than a moderate amount of raw performance, highlights these differences. It tends to sample outside the intended part of its texture atlas. Any safeguards have limited efficacy or only make things worse, with Mojang not really knowing how these things work. Results often vary by GPU, NVIDIA being most robust.
Do you happen to know what GPUs are doing to prevent these problems? Say, is NVIDIA more accurate or does it just happen to work particularly well with interpolants that are constant along an edge? I can see how staying in barycentric coordinates (sourced directly from the rasterizer) for longer could have that effect, as opposed to transforming to screen space early and stepping in pixels. Although I recall AMD’s GCN uses barycentric coordinates. Hmm. Could be more subtle. It’s also possible interpolants are nudged so dangerous errors are pushed out of the triangle. You’d think I’d have noticed in some of my tests, though.
I do know it really is or was out there because an R300 spec I once skimmed through described a register to configure it. Did you know the thing had a mode with 1/12 pixel precision, or ~3.6 subpixel bits? As if the usual 1/16 wasn’t imprecise enough! :-) Must’ve had to do with its 6x MSAA mode. Apparently it could secretly do 3x as well. I also learned it used traditional triangle-splitting clipping. I was only beginning to learn about these things at the time I owned one, but when it broke on me it occasionally revealed how triangles at the edge were sometimes split.
In the section on Integer overflows, at the end you have
2^(2p+1) – 2^(p+2) + 2 <= 2^(2p+1) – 2
Shouldn't it be <= 2^(2p+1) + 2 ? Why does the sign of the 2 at the end change? Maybe this is just some basic math I'm not seeing…
See the rest of the sentence below: “since p is always nonnegative”. p >= 0 implies 2^(p+2) >= 2^2 = 4, so 2^(2p+1) – 2^(p+2) + 2 <= 2^(2p+1) – 4 + 2 = 2^(2p+1) – 2.
Hi Fabian, thank you very much for the series. Even the non-simdified version beats my previous line sweeping one.
I have a question which I have been unable to answer for 2 days. I don’t understand what this piece of code is for (although it does work, and without it the renderer will indeed skip some pixels):
// Round start position up to next integer multiple
// (we sample at integer pixel positions, so if our
// min is not an integer coordinate, that pixel won’t
// be hit)
minX = (minX + subMask) & ~subMask;
minY = (minY + subMask) & ~subMask;
Suppose we multiply everything by 16, so subMask is 0xFFFF and subStep is 0x10000. So essentially we’re not rounding, but ceiling the values of minX and minY to the next multiple of 16.
Here, I’ve drawn a picture: https://s24.postimg.org/ttl2564hh/rasterize.png
The green triangle is the triangle we’re trying to draw, and the red one is the triangle drawn without subpixel precision (which we can ignore).
If we do include those 2 lines of code above, we’ll sample the green points, and if we omit them, we’ll sample the purple points.
Question: why are the green points better? It is counter-intuitive to me, since the first purple sample starts exactly where the triangle vertex is, which would make sense.
Thanks
Ceiling is a form of rounding. (Namely, always rounding up.)
It’s not particularly important which kind of sampling grid you use (e.g. the exact choice of sample points doesn’t change things substantially), but it is important that all triangles on the screen agree on what the grid is.
Consider two triangles with a shared edge if each uses their own grid (the purple points in your example). Then pixels near the shared edge may either be hit twice or not at all, neither of which is desirable.
OMG of course, that’s exactly why we’ll see gaps between triangles. Thank you very much!
I realise this is a fairly old series but it’s been very useful! Note – I think you can do better for the orient2D bound.
If we take the eq and expand we can get
ax(by-cy)+bx(cy-ay)+cx(ay-by)
If we say that on x we have x signed bit integers, and y, y signed bit integers, let x=n+1 and y=m+1, therefore
-2^n <= ax, bx, cx <= 2^n – 1
-2^m <= ay, by, cy = 1 therefore 2^x >= 2, so 1 – 2^x – 2^y <= -3
This finally gives 2^(x+y) – 2^x – 2^y + 1 <= 2^(x+y) – 3
This means that we require only an x+y+1 bit signed integer as the upper bound for such an integer is 2^(x+y) – 1. This also works for the lower bound similarly, however it is the upper bound that is tighter.
I first realised this when attempting a verilog implementation and was trying to use formal verification to prove safety – I noticed that my test passed for x+y+1 and working through it seems to hold.
wow. i see this is 10 years old! it’s really good