View frustum culling
Recently stumbled across this series by Zeux. It’s well written, but I have one tiny objection about the content. The money quote is in part 5, where he says that “there is p/n-vertex approach which I did not implement (but I’m certain that it won’t be a win over my current methods on SPUs)”. Hoo boy. Being certain about something you don’t know is never a good strategy in programming (or life in general for that matter). View-frustum culling for AABBs is something I’ve come across multiple times in the 12 years that I’ve been seriously doing 3D graphics. There’s tons of nice tricks of the trade, and even though all of them are published somewhere, most people don’t bother looking it up (after all, the obvious algorithm is simple enough and not very slow) – incidentally, there’s two books that are most likely already in your office somewhere (if you’re a graphics or game programmer) that you should consult on the topic: “Real-Time Rendering” (16.10, “Plane/Box Intersection Detection”) and “Real-Time Collision Detection” (5.2.3, “Testing Box Against Plane”). Both describe a very slick implementation of the “p/n-vertex” approach. But I’m gonna take a trip down memory lane and explain the various approaches I’ve been using over the years (don’t expect optimized implementations of all of them, I’m just going to explain the basic idea of each test and then move on, for the most part).
Method 1: Test all 8 box vertices against object-space (or world-space) planes
That’s the approach used in the first half of Zeux’s articles; look it up if you don’t know the details, but it’s really pretty straightforward.
Method 2: Transform box vertices to clip space, test against clip-space planes
That’s what Zeux uses starting from part 5 of his series. The big advantage is that the homogeneous clip-space plane equations are very simple: The 6 clip-space plane inequalities are 

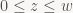
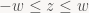
Method 2b: Saving arithmetic ops
If your target platform doesn’t have fused multiply-adds, you can shave a fair number of arithmetic ops by observing that all the transformed vertex components are computed like this:
v[i].x = mat[0][0] * ((i & 1) ? max.x : min.x)
+ mat[0][1] * ((i & 2) ? max.y : min.y)
+ mat[0][2] * ((i & 4) ? max.z : min.z)
+ mat[0][3];
v[i].y = mat[1][0] * ((i & 1) ? max.x : min.x)
+ mat[1][1] * ((i & 2) ? max.y : min.y)
+ mat[1][2] * ((i & 4) ? max.z : min.z)
+ mat[1][3];
// and so on for z and w
If you transform them all separately, you get 8 (verts)*4 (output components)*3 (input components)=96 multiplies. But you can calculate e.g. “mat[0][0] * min.x” and “mat[0][0] * max.x” just once and use these common subexpressions for the 4 transformed vertices each that refer to it, which yields 6 (min/max values) * 4 (different matrix elements they get multiplied by)=24 multiplies, for an overall 4x reduction in number of muls. You can also save a few adds at the same time by folding the ” + mat[i][3]” into the temporary products for one of the axes, e.g. the z axis, so you compute (and cache) “mat[i][2] * {min,max}.z + mat[i][3]”.
If you don’t have FMAs, you now do 24 muls and 8+64=72 adds instead of 96 muls and 96 adds. With FMAs though, this isn’t really interesting – you turn 96 FMAs into 16 muls, 8 FMAs and 64 adds, so the number of arithmetic ops (and usually also the execution time) stays the same, but you need more registers to store the cached common subexpressions.
Method 3: Partial homogeneous transform
You can save some more work if you only allow affine model-view transformations and require your projection to be in the usual format (note this covers both perspective and orthogonal projections):

You can simply throw the z component out – you don’t need it, the perspective projection puts the view-space z into w, and you can explicitly check it against the near / far planes. You end up with the modified plane equations 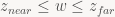
For SIMD implementations, you can realize all of this benefit or don’t get any of it, depending on whether you store rows or columns in your SIMD registers. If you compute a vector of z values (as Zeux does), you win – just don’t compute it, and presto, a 25% reduction in arithmetic ops to get your clip-space coordinates. In case you still want the clip-space z later (like for occlusion culling), you can compute it from w using one FMA at the end: 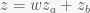
Method 4: Don’t test all vertices against all planes
This is what Zeux refers to as the “p/n-vertex” approach. It’s in some sense complimentary to the homogeneous clip-space approach: The clip-space test transforms all vertices into a space where it’s trivial to check if they lie inside the frustum, i.e. it makes the plane tests cheaper. This approach leaves the planes as they are but considers fewer vertices. The basic idea is to go back to the original algorithm and look at the tests we’re doing to decide whether the box is completely outside a given plane or not:
bool inside = false;
for (j=0; j < 8; ++j)
if (dot(vertex[j], plane) > 0) {
inside = true;
break;
}
So we check whether there’s at least one vertex that is partially inside the given plane. Equivalently, we can check if the max of all the dot products is positive. The 8 vertices we have are the 8 possible combinations of picking min/max for the x, y and z coordinates. If you write out the dot product equations, all 8 of them match this template:
{min.x,max.x} * plane.x + {min.y,max.y} * plane.y
+ {min.y,max.z} * plane.z + plane.w
(instead of +plane.w, i.e. treating a plane as a homogeneous 4-vector, you might also use a plane in normal form and subtract plane.d – it doesn’t matter). The 3 terms involving the box coordinates are independent, so we can just maximize them separately. So if we want to find the max of all the dot products, we get:
float d = max(aabb->min.x * plane.x, aabb->max.x * plane.x)
+ max(aabb->min.y * plane.y, aabb->max.y * plane.y)
+ max(aabb->min.z * plane.z, aabb->max.z * plane.z)
+ plane.w;
bool inside = d > 0; // or skip the add and test >-plane.w
Note that this implicitly picks whichever vertex of the box is “most inside” the plane and uses that. If you replace all the “max” calls with “min”, you get the vertex that’s “most outside”. If the dot product is still positive, the box is completely inside the plane. Or you can compute both at once (do the multiplies once, then a pair of min/max operations) and get a full tri-state test result (inside, outside, intersecting).
To test box against frustum, you simply do this 6 times, once for each of the frustum planes.
Method 4b: A different box representation
This is the method you’ll find in both “Real-Time Rendering” and “Real-Time Collision detection”. The basic idea is to represent the AABB not by its min/max corners, but to use its center and half-extent vectors instead. They are easy to compute:
center = 0.5 * (min + max); extent = 0.5 * (max - min);
so the 8 vertices of the box have the coordinates:
v.x = center.x ± extent.x; v.y = center.y ± extent.y; v.z = center.z ± extent.z;
plugging this into the dot product equations and using linearity of the dot product, we get:
d = dot(center, plane) ± extent.x * plane.x
± extent.y * plane.y ± extent.z * plane.z;
which is trivial to maximize – just use the absolute value for each term. Since the components of “extent” are all positive, this boils down to:
d = dot(center, plane) + extent.x * fabs(plane.x)
+ extent.y * fabs(plane.y) + extent.z * fabs(plane.z);
and since plane is (expected to be) constant for some number of boxes, we can compute the abs once (it’s just an and with a constant anyway) and keep the results in a register – it boils down to having a second vector, absPlane, that’s just the componentwise abs of plane. Using this notation, we get:
float d = dot(center, plane); float r = dot(extent, absPlane); if (d + r > 0) // partially inside if (d - r >= 0) // fully inside
(I’ll ignore the “fully inside” case for the rest of the article – just wanted to show how easy it is to get that information out of the test if you care). Just as in the previous method, you probably don’t want to add plane.w to d, but just compare d+r against -plane.w instead. That’s 12 3D dot products to test against 6 planes, assuming you have your AABB in center-plus-half-extent format.
For comparison, the optimized homogeneous test from Method 3 computes the equivalent of 24 dot products to transform the 8 box vertices into clip space. Even with the slight extra work of having to compute “center” and “extent” first if we use a min/max representation, this is still nothing to be sneered at. But I’m not done yet!
Method 4c: Store center and extent directly
If you store your bboxes for culling as center/extent directly, you’re really down to 12 dot products plus 6 compares. This isn’t the worst representation to use – center/extent AABBs are also convenient for collision detection (in fact, the test we’re using is basically just a variant on a separating axis test).
Method 4d: Keep min/max but still save a bit of work
If you want to stay with min/max for other reasons, you can still save some work: you don’t really need to multiply center / extent by 0.5. You can just work with
center = min + max; extent = max - min;
this multiplies the dot products by 2 (linearity!) which is no problem. The only thing that changes is that you now compare against “-plane.w * 2”, which you can just compute once when you set up your planes and store. No extra work in the inner loop at all. Not a lot of instructions saved this time, but hey, it’s a simple optimization, so why not do it?
Method 5: If you really don’t care whether a box is partially or fully inside
All variants of the test before could still distinguish partially inside (intersecting) boxes from ones that are fully inside (this goes for the homogeneous tests as well, using the analog of Cohen-Sutherland clipping outcodes; Google it if you don’t know the technique). I’m now gonna throw that away in the pursuit of even more speed :). The test we’re looking at (per-plane) is:
return dot3(center, plane) + dot3(extent, absPlane) > -plane.w;
The 2 dot products are somewhat annoying. They’re “almost” with the same value, except for sign. If we could rewrite both as dot products with “plane”, we could use linearity and do one vector add and one dot product. To do this, we need to get the sign flips into extent – something like:
return dot3(center + extent * signFlip, plane) > -plane.w;
where signFlip = (sgn(plane.x), sgn(plane.y), sgn(plane.z)) using the standard signum function and using componentwise multiply for the product “extent * signFlip”. For scalar code, you’re best off using this code and precomputing a “signFlip” vector for each “plane” (it replaces “absPlane”). For SIMD though, we can usually do some amount of integer math on IEEE floating-point values that makes this much easier: We can extract the signs of “plane” by doing a binary and with the mask 0x80000000 and replace “extent * signFlip” with a XOR:
vector4 signFlip = componentwise_and(plane, 0x80000000); return dot3(center + xor(extent, signFlip), plane) > -plane.w;
Voila, down to 6 dot products, 6 vector adds, 6 xors and 6 compares to test against 6 planes (plus a very small amount of setup). There’s other tricks you can do, but this particular test is so tight that it’s really hard to get any wins out of common tricks. For example, you can exploit that the near and far plane are usually parallel (we implicitly used this for Method 3). This saves some work with the Method 4-style tests, but it’s a wash for this variant.
Is it possible to do better? Maybe. I have no idea. I can however say that this is the fastest method I know right now.
SIMDifying it
From here, there’s several ways of getting a nice SIMD implementation. Which one to choose depends on your data layout.
If it’s an option, the fastest variants for 4-way SIMD usually test 4 boxes at a time. You have 6 vectors (min.{xyz}/max.{xyz} or center.{xyz}/extent.{xyz}) that each contain the respective value for 4 different boxes. You then run through what is basically a scalar version of the code – just processing 4 elements every time. If you fully control the layout, store center/extent, for 4 boxes at a time, as 6 aligned vectors. The resulting code will be very fast indeed.
If you don’t want or can’t use this representation and test single boxes, there’s some amount of inefficiency you’ll just have to accept, since you’ll be wasting some of your vector lanes for part of the computation. That said, the resulting code, assuming min/max and using all the tricks documented here, looks something like this (using SPU intrinsics and similar data structures as Zeux, for comparison):
// load planes
// (keep this in registers if possible!)
qword sign_mask = si_ilhu(0x8000u);
qword plane_x0 = (qword) frustum->plane_x0;
qword plane_x1 = (qword) frustum->plane_x1;
qword plane_y0 = (qword) frustum->plane_y0;
qword plane_y1 = (qword) frustum->plane_y1;
qword plane_z0 = (qword) frustum->plane_z0;
qword plane_z1 = (qword) frustum->plane_z1;
qword plane_w0 = (qword) frustum->plane_w0;
qword plane_w1 = (qword) frustum->plane_w1;
// load AABB
qword min = (qword) aabb->min;
qword max = (qword) aabb->max;
qword extent = si_fs(max, min);
qword center = si_fa(max, min);
// compute the dot products
qword t0, t1;
qword dot0, dot1;
t0 = si_fa(SPLAT(center, 2), si_xor(SPLAT(extent, 2),
si_and(plane_z0, sign_mask)));
t1 = si_fa(SPLAT(center, 2), si_xor(SPLAT(extent, 2),
si_and(plane_z1, sign_mask)));
dot0 = si_fma(t0, plane_z0, plane_w0);
dot1 = si_fma(t1, plane_z1, plane_w1);
t0 = si_fa(SPLAT(center, 1), si_xor(SPLAT(extent, 1),
si_and(plane_y0, sign_mask)));
t1 = si_fa(SPLAT(center, 1), si_xor(SPLAT(extent, 1),
si_and(plane_y1, sign_mask)));
dot0 = si_fma(t0, plane_y0, dot0);
dot1 = si_fma(t1, plane_y1, dot1);
t0 = si_fa(SPLAT(center, 0), si_xor(SPLAT(extent, 0),
si_and(plane_x0, sign_mask)));
t1 = si_fa(SPLAT(center, 0), si_xor(SPLAT(extent, 0),
si_and(plane_x1, sign_mask)));
dot0 = si_fma(t0, plane_x0, dot0);
dot1 = si_fma(t1, plane_x1, dot1);
// do the test
qword test = si_orx(si_nand(dot0, dot1)); // all dots >= 0
return si_to_int(test) >> 31;
I don’t have a SPU compiler installed here, so excuse me if there’s bugs in the above program, I have only typed it into WordPress, not tried it! You also need to set up the planes up correctly. They’re stored in transposed form: plane_x0 is plane.x for planes 0..3, plane_x1 is plane.x for planes 4 and 5 (and 0 in the other components), and so on. And plane_w0/plane_w1 are also multiplied by 2 (compare Method 4d above).
Anyway, so what’s the tally? Ignoring the loads for the splat constants (I’d much rather have a compiler figure it out and this post has taken me way too long already), we get:
- 1 ilhu (even) for the plane equations
- 8 lqd (odd) for the plane equations
- 6 and (even) for the plane equations
- 2 lqd (odd) for the bbox
- 6 shufb (odd) for the splatting
- 7 fa (even)
- 1 fs (even)
- 6 fma (even)
- 6 xor (even)
- 1 nand (even)
- 1 orx (odd)
- 1 rotmi (even) for the return value
For a total of 29 even and 17 odd instructions (plus some constant loading!) if you process one bbox at a time. Everything marked with “for the plane equations” needs to be done only once when you’re testing multiple bboxes against the same planes (the constant setup for the splats also needs to be done only once). To process 4 bboxes at a time, I get 7+22*4 = 95 even instructions and 8+9*4 = 44 odd instructions, plus some change to set up the constants. Sadly pretty unbalanced, and I have no idea how the schedule works out, but we get a theoretical min of about 95 cycles per 4 boxes, or just under 24 cycles per box – less than half the theoretical min for Zeux’s code. And with 4 boxes in parallel, we have 8 independent instructions in every group (except for the very end), which should be enough to hide the 6-cycle latency of the floating-point arithmetic instructions nicely. I have no idea how it really shakes out in practice (need to check this later), but even if it doesn’t go that well, I’d be surprised to see this take much more than 40 cycles/box.
Of course, it doesn’t compute the clip-space coordinates in the process either – if that’s important to you, it definitely makes sense to go with the homogeneous approach (though you should still consider dropping the z until you actually need it).
UPDATE: As Zeux points out, the cycle count comparison is bogus since he computes the world-view-projection matrix in the process and works with an object-space AABB. My code assumes a world-space AABB – you’d need to either transform the planes into object space or the AABB into world space (where it’s an OBB) to make this work. Both make the test more expensive, so it’s not a fair comparison. And of course, if you want the world-view-projection matrix anyway, that offsets the cost of the computation considerably.

While I haven’t read your post yet :) I’ll comment on the p/n vertex.
I’ve only implemented p/n vertex as a prototype, and the initial implementation has roughly the same performance as the clip-space version (though it can be optimized).
However, since the clip-space extents enable me to do additional culling, the p/n-vertex will be more costly if I were to use it in the production code.
Also, your code does not compute the worldviewproj matrix ;)
I mention that depending on the application you’d want to use the homogeneous version – but I have some speed improvements for that as well, though no code :)
“Also, your code does not compute the worldviewproj matrix ;)”
Er, yeah. Oops :)