Row major vs. column major, row vectors vs. column vectors
Row-major vs. column-major is just a storage order thing and doesn’t have anything to do with what kind of vectors you use. But graphics programmers tend to be exposed to either GL (which uses column-major storage and column vectors) or D3D (which used row-major storage and row vectors in its fixed function pipeline, and still uses that convention in its examples), so they think the two things are tied together somehow. They’re not. So let’s disentangle them! But before we start, a small apology: In this article I’ll be using both “formula” and “code” notation for variable names, which is a typographic faux pas but necessary because WordPress isn’t very good at lining up 
Row/column major
There’s no disagreement about how plain arrays are stored in memory: Any programming language that supports a plain (not associative) array type just stores the elements sequentially. Once a language supports multidimensional arrays however, it needs to decide how to squeeze the 2D arrangement of data into a 1D arrangement in memory, typically as an 1D array. One classical use case for multidimensional arrays are matrices:
Given a Matrix 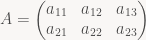
- Row-major storage traverses the matrix by rows, then within each row enumerates the columns. So our
Awould be stored in memory asa11, a12, a13, a21, a22, a23. This matches reading order in English and most other Western languages. Row-major storage order for 2D arrays is used by C / C++, the Borland dialects of Pascal, and pretty much any language that was designed since the mid-1970s and supports multidimensional arrays directly. (Several newer languages such as Java don’t support 2D arrays directly at all, opting instead to represent them as an 1D array of references to 1D arrays). It’s also the dominant storage order for images. The position of the element at rowi, columnjin the underlying 1D array is computed asi*stride + j, wherestrideis the number of elements stored per row, usually the width of the 2D array, but it can also be larger. - Column-major storage traverses the matrix by columns, then enumerates the rows within each column.
Awould be stored in memory asa11, a21, a12, a22, a13, a23. Column-major storage is used by FORTRAN and hence by BLAS and LAPACK, the bread and butter of high-performance numerical computation. It is also used by GL for matrices (due to something of a historical accident), even though GL is a C-based library and all other types of 2D or higher-dimensional data in GL (2D/3D textures etc.) use row-major.
Let me reiterate: Both row and column major are about the way you layout 2D (3D, …) arrays in memory, which uses 1D addresses. In the example (and also in the following), I always write the row index first, followed by the column index, i.e. 
A in row i and column j, no matter which way it ends up being stored. By the same convention, I write “3×4 matrix” to denote a matrix with 3 rows and 4 columns, independent of memory layout.
Matrix multiplication
The next ingredient we need is matrix multiplication. If A and B are a 
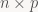
C=AB is a 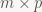
i and column j of matrix C is computed as the dot product of the i-th row of A and the j-th column of B, or in formulas 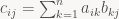
The important point to note here is that for a matrix product AB you always compute the dot product between rows of A and columns of B; there’s no disagreement here. This is how everyone does it, row-major layout or not.
Row and column vectors
So here’s where the confusion starts: a n-element vector can be interpreted as a matrix (a “typecast” if you will). Again, there’s two canonical ways to do this: either we stack the n numbers vertically into a 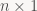

n-element 1D array.
Here’s where the confusion starts: To transform a vector by a matrix, you first need to convert the vector to a matrix (i.e. choose whether it’s supposed to be a column or row vector this time), then multiply the two. In the usual graphics setting, we have a 4×4 matrix T and a 4-vector v. Since the middle dimension in a matrix product must match, we can’t do this arbitrarily. If we write v as a 4×1 matrix (column vector), we can compute Tv but not vT. If v is instead a 1×4 matrix (row vector), only vT works and Tv leads to a “dimension mismatch”. For both column and row vectors, the result of that is again a column or row vector, respectively, which has repercussions: if we want to transform the result again by another matrix, again there’s only one place where we can legally put it. For column vectors, transforming a vector by T then S leads to the expression 
T then S” is given by the matrix ST. For row vectors, we get 
TS. Small difference, big repercussions: whether you choose row or column vectors influences how you concatenate transforms.
GL fixed function is column-major and uses column vectors, whereas D3D fixed function was row-major and used row vectors. This has led a lot of people to believe that your storage order must always match the way you interpret vectors. It doesn’t. Another myth is that matrix multiplication order depends on whether you’re using row-major or column-major. It doesn’t: matrices are always multiplied the same way, and what that product matrix means depends on what type of vector you use, not what kind of storage scheme.
One more point: say you have two n-element vectors, u and v. There’s two ways to multiply these two together as a matrix product (yes, you can multiply two vectors): if u is a row vector and v is a column vector, the product is a 1×1 matrix, or just a single scalar, the dot product of the two vectors. This operation is the (matrix) inner product. If instead u is a column vector and v is a row vector, the result is a 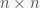
u and v don’t match, but I ignore that case here). The outer product isn’t as common as its more famous cousin, but it does crop up in several places in Linear Algebra and is worth knowing about. I bring these two examples up to illustrate that you can’t just hand-wave away the issue of vector orientation entirely; you need both, and which one is which matters when the two interact.
With that cleared up, two comments: First, I recommend that you stick with whatever storage order is the default in your language/environment (principle of least surprise and all that), but it really doesn’t matter whether you pick row or column vectors – not in any deep sense, anyway. The difference between the two is purely one of notation (and convention). Second, there happens to be a very much dominant convention in maths, physics and really all the rest of the world except for Computer Graphics, and that convention is to use column vectors by default. For whatever reason, some of the very earliest CG texts chose to break with tradition and used row vectors, and ever since CG has been cursed with a completely unnecessary confusion about things such as matrix multiplication order. If you get to choose, I suggest you prefer column vectors. But whatever you do, make sure to document whatever you use in your code and stick with it, at least within individual components. In terms of understanding and debuggability, a single source file that uses two different vector math libraries with opposite conventions (or three – I’ve seen it happen) is a catastrophe. It’s a bug honeypot. Just say no, and fix it when you see it.

If fixed pipeline for D3D was using row-major layout, the default packing for HLSL matrix is now column-major but for example for D3DX9/D3DX10/D3DX11 Effects SetMatrix method is taking a matrix stored in row-major order. But internally, they are transposing the matrix to the HLSL matrix packing which is by default column-major (but can be changed to row-major with a pragma). Don’t know if Effects is using row-major for backward compatibility with fixed pipeline…
On the other hand, if you are uploading your matrix directly to a constant buffer in D3D10/D3D11, without using D3DX Effects, you will have to transpose your row-major matrix (assuming math lib is in row-major) to a colum-major matrix.
HLSL is all over the place. Their default matrix storage is col-major, but there’s the global #pragma to switch the default, and you can also change it as part of a regular variable declaration. If you however construct a
floatNxMin code from an initializer list, the items in that list are always row-major.What XNAMath, HLSL and D3D samples do is internally inconsistent to such an extent that I think it’s a total waste of time to match their behavior. Of course, that may be colored by me mostly doing multi-platform work, where using libraries like XNAMath or the Effects framework that only work on a subset of target platforms has a net negative value in the first place.
I prefer D3D layout, because it provides a lot of useful shortcuts that save memory. For example, you have a matrix that represents an object in 3D space, and want to find the direction of it’s local Z axis: (the way it is pointing), well that’s just the 3rd vector in the matrix. Similarly, if the object shoots a missile due sideways: well, that’s just the 1st vector in the matrix.
Since it’s likely that high speed code will access these vectors, it’s convenient to store them in a quickly retrieved way.
And I prefer OpenGL layout because it provides the exact same shortcuts.
@Gil Colgate
You can also store an object orientation with only the “up” and “forward” vectors (only 2 vecs) if you really want to save memory, matrix layout does not matter. If you need the “side” vector it’s straightforward to compute (a simple cross product).
You can also store the orientation in more compact way with quaternions.
Hi.
“GL fixed function is column-major and uses column vectors, whereas D3D fixed function was row-major and used row vectors.”
No, it isn’t. It uses column-major notation in the documentation, but it does not use column-major storage. http://bit.ly/KFrFem (opengl.org FAQs)
Quote from the above link:
“For programming purposes, OpenGL matrices are 16-value arrays with base vectors laid out contiguously in memory. The translation components occupy the 13th, 14th, and 15th elements of the 16-element matrix, where indices are numbered from 1 to 16 as described in section 2.11.2 of the OpenGL 2.1 Specification.
Column-major versus row-major is purely a notational convention. Note that post-multiplying with column-major matrices produces the same result as pre-multiplying with row-major matrices. The OpenGL Specification and the OpenGL Reference Manual both use column-major notation. You can use any notation, as long as it’s clearly stated.
Sadly, the use of column-major format in the spec and blue book has resulted in endless confusion in the OpenGL programming community. Column-major notation suggests that matrices are not laid out in memory as a programmer would expect.”
See this code snippet (it has output on the page): http://codepad.org/qbL9zrTc
M[row=3][column=0] = M[12]. It’s the same as Direct3D. (D3DXMatrix (in order): _11, _12, _13, _14, _21, _22, _23, _24, _31, _32, _33, _34, _41, _42, _43, _44. Where _41, _42, _43 are the translation component, which line up with 12, 13, and 14.)
You have at least two articles claiming OpenGL uses column-major storage. According to the above you’re incorrect. The documentation uses column-major notation, not storage. OpenGL.org lists the translation components at 12, 13, and 14. If column major storage were used, then they would be at 3, 7, and 11 instead.
My argument is strictly for the fixed-function pipeline. If I’m wrong, please correct me.
Cheers,
Aaron
“No, it isn’t. It uses column-major notation in the documentation, but it does not use column-major storage. http://bit.ly/KFrFem (opengl.org FAQs)”
The OpenGL.org FAQs are not a normative document. Section 2.11.2 of the OpenGL spec (that the FAQ entry cites!) is. The exact quote is: (GL 2.1 spec, page 43)
“LoadMatrix takes a pointer to a 4×4 matrix stored in column-major order as 16 consecutive floating-point values, i.e. as [matrix with indices numbered in column-major storage order]. (This differs from the standard row-major C ordering for matrix elements. If the standard ordering is used, all of the subsequent transformation equations are transposed, and the columns representing vectors become rows.)”
The section you quote from the OpenGL FAQ is making the exact same conceptual mistake I am complaining about in this post to begin with. There is no such thing as a “column-major matrix” in math. Storage order is purely an artifact of having to store a 2-dimensional layout in 1-dimensional memory. A matrix is a mathematical entity; storage order, data type etc. are details of the representation of that entity in computer memory. From a mathematical perspective, a matrix is a matrix, and all matrix product have to follow a simple rule: the middle dimensions have to match. I cover this (and what it means for where you can put vectors) in my post.
However, you can transpose all matrices and vectors involved and multiply them in reverse order (reversing the order is a result of the identity (A*B)^T = B^T * A^T). This gives transposed but otherwise identical results, i.e. column vectors and row vectors trade places, but the rest is the same. This transposition is what is alluded to the in parenthesized statement from the spec. Transposition is an isomorphism – the two forms are equivalent, and there is no intrinsic reason to prefer one over the other. Practically speaking though, the column vector form is the version you’ll find in the vast majority of maths and physics textbooks and papers.
Column-major storage and row-major storage are also closely related in that A stored in row-major form and the transpose of A stored in column-major form result in the same bytes in memory (as long as there’s no holes between rows/columns at least). This tends to confuse matters further.
OpenG fixed-function is specced as using column vectors and column-major storage. D3D fixed-function is specced as using row vectors and row-major storage. If you look at an individual matrix (say translation by (tx, ty, tz)), the D3D and GL versions look exactly the same in memory. However, they do not behave the same way: in OpenGL, the matrix that represents “first A then B” is B*A; in D3D, it is A*B.
“You have at least two articles claiming OpenGL uses column-major storage. According to the above you’re incorrect. The documentation uses column-major notation, not storage.”
Above, I have quoted the line from the GL spec that explicitly mentions how GL uses column-major storage order.
@fgiesen
Ah, okay. I was mistaken then. Thank you for your reply.
Cheers,
Aaron
@aaronmiller42
“OpenGL.org lists the translation components at 12, 13, and 14. If column major storage were used, then they would be at 3, 7, and 11 instead.”
It’s quite the opposite.
In the homogeneous transformation matrix, the last row is assumed to be (0,0,0,1). In the column-major order it means that the elements at index 3, 7 and 11 are 0.0, the 15th is 1.0.
If the OpenGL clearly states that it considers translation components at 12, 13, 14, the “correct” way of using this matrix to transform a point is: M*p.
@bill
Hello! I appreciate your time to comment.
fgiesen remarked that Direct3D 11 uses row major storage and notation. Microsoft’s notation then matches the storage order. Please see the Direct3D 9 Programming Guide: http://msdn.microsoft.com/en-us/library/windows/desktop/bb206269(v=vs.85).aspx
Here’s a picture of the relevant image: http://i.msdn.microsoft.com/dynimg/IC511488.png
As you can see in the image above, the translation’s x, y, and z coordinates are in the last row.
Now, review the D3DMATRIX structure: http://msdn.microsoft.com/en-us/library/windows/desktop/bb172573(v=vs.85).aspx
Here, they list it as row-major: “An array of floats that represent a 4×4 matrix, where i is the row number and j is the column number. For example, _34 means the same as [a34], the component in the third row and fourth column.”
Let’s revisit OpenGL.org again: “The translation components occupy the 13th, 14th, and 15th elements of the 16-element matrix, where indices are numbered from 1 to 16 as described in section 2.11.2 of the OpenGL 2.1 Specification.”
In the D3DMATRIX structure, components _41, _42, and _43 are the translation component. This corresponds to indices 12, 13, and 14 (zero-based), assuming you accessed it as an array. Again, fgiesen remarks that row-major storage is used by Direct3D, but not OpenGL. (Please note, I’m referring to the fixed-function pipeline only. In Direct3D the default storage for matrices in shaders is column-major.) My argument is that the OpenGL specification (fairly reliable) claims otherwise: the translation components MATCH between Direct3D and OpenGL (again, fixed-function).
Also: http://en.wikipedia.org/wiki/Row-major_order for more information on the differences between row-major and column-major.
If you wanted to represent your matrices with column-major notation but row-major storage, you could do something like this:
typedef struct {
float _11,_21,_31,_41, _12,_22,_32,_42, _13,_23,_33,_43, _14,_24,_34,_44;
} mat4_t;
That way _14, _24, and _34 match column-major notation. e.g.,
1 0 0 x
0 1 0 y
0 0 1 z
0 0 0 1
Instead of row-major notation:
1 0 0 0
0 1 0 0
0 0 1 0
x y z 0
Please provide citation for why I’m wrong if I am. I’m not stubborn on the issue, but you haven’t cited any source, period. Let alone reliable sources. However, from what I’ve seen, and the double-checking that I’ve done, I believe I am correct.
Cheers,
Aaron
“My argument is that the OpenGL specification (fairly reliable) claims otherwise: the translation components MATCH between Direct3D and OpenGL (again, fixed-function).”
That is correct, and I never said anything to the contrary. Indeed, this kind of confusion is exactly why I wrote the post in the first place: storage order is only half of the issue, you also need to specify what type of vectors you use!
Let’s do column vectors first, so our expression looks like this:
it’s straightforward to verify that this is indeed a translation (just multiply it out). Now let’s look at what happens if we use the exact same matrix in a row-vector expression (note we have to switch places between matrix and vector to make the matrix product dimensions work out):
[1 0 0 tx] [0 1 0 ty] [x' y' z' w'] = [x y z w] * [0 0 1 tz] = [x y z x*tx+y*ty+z*tz+w] [0 0 0 1]Clearly not what we want. Indeed, when using row vectors, a translation matrix is the identity with the last row replaced by “tx ty tz 1” – the transpose of our column-vector translation matrix (this is just the “transpose everything and reverse order of multiplication” thing I mentioned earlier).
So, while OpenGL defaults to column-major storage and D3D defaults to row-major storage, they don’t store the same thing – the matrices themselves are different (transposed in fact) because of the different types of vectors they use.
ryg, Great post. I’ve seen these same myths and pitfalls.Like you suggest it is very useful to know where these concepts come from and saves a lot of random tweaking and hand-waving. This also reminds me how a problem can be more easily solved by looking at it in a more appropriate frame of reference.
“The important point to note here is that for a matrix product AB you always compute the dot product between rows of A and columns of B; there’s no disagreement here.”
You can also compute each resulting column as a linear combination of the columns of A.
“This is how everyone does it, row-major layout or not.”
This is not how Strassen, Coppersmith or Winograd do it.
Ok this is irrelevant to your main point, but I like to disagree.
Yes, or use one of the other 4 possible loop orderings for ordinary matrix multiplication. Doesn’t matter (in exact arithmetic anyway); all loop orderings compute the same results, they just execute operations in different orders.
True. But neither Strassen nor Coppersmith-Winograd matrix multiplication are even remotely relevant for the matrix sizes used in GL/D3D or other 3D APIs. :)
Hi, quick question since I’m still lost. HLSL and GLSL read inputs as column major storage so in memory it’s the same right ? now in the shader code, HLSL does a v*M faster than M*v, if I stick to the row-vector style in HLSL and column style in GLSL I must transpose my matrices for one of the 2 versions right ?
HLSL supports both row-major and column-major storage. The default if you don’t do anything is column-major, but within a shader you can either set the global default for all matrices to row-major using a pragma, or specify row_major/col_major per matrix if you want to.
Either way, there’s no performance difference between v*M and M*v.
I think I’m gonna use the pragma solution for now even if it is harder to maintain shaders with different math styles. I found a post in which someone states the assemblies of the 2 versions of mul are different and one instruction is preferred by nvidia over others.. I’ll eventually check. Thanks for the fast answer btw.
One generates a mul and 3 mads, the other generates 4 dp4s, but at least for PC GPUs there’s no perf difference in this case. NVidia GPUs since Tesla (GeForce 8 series) and AMD GPUs since GCN are “scalar”, that is, they do not vectorize “horizontally” within such instructions; all the parallelism comes from shading lots of different vertices/pixels at once. For such scalar architectures, both DP4 and MUL/MAD compile to essentially the same code (except for the matrix accesses being transposed). It is the same performance on pre-GCN (VLIW) AMD hardware as well.
“Row-major vs. column-major is just a storage order thing and doesn’t have anything to do with what kind of vectors you use.”
That means, that regardless if you have row/column major notation, you still access an array as A(i, j), by implying i-th row and j-th column?
Yes, when talking about matrices anyway.
Very useful post. Thanks a lot!
That’s the best explanation I’ve read on this topic so far! You made it absolutely clear that this is just about storage order and nothing else. Sadly, many resources (e.g. the otherwise excellent Scratchapixel) confuse the matter more than necessary in their attempt to actually clarify it… Cheers! :)
I came up with an approach that I quite like in a math library I put together where at compile time you have to opt in to row major or column major (to make the decision deliberate and explicit). If you pick column, the first elements in storage order are the column, if you pick row, the first elements in storage order are the row, and then to access the opposite col/row it will look at the interleaved elements (there’s a define to switch the behaviour for the different functions – so in row major, accessing the row is fast, but the column is slightly slower, and in col major, accessing the column is fast but accessing the row will be slightly slower). This means whichever convention you pick, the data access pattern will be optimal. This is the library for reference – https://github.com/pr0g/as.