rANS notes
We’ve been spending some time at RAD looking at Jarek Duda’s ANS/ABS coders (paper). This is essentially a new way of doing arithmetic coding with some different trade-offs from the standard methods. In particular, they have a few sweet spots for situations that were (previously) hard to handle efficiently with regular arithmetic coding.
The paper covers numerous algorithms. Of those given, I think what Jarek calls “rANS” and “tANS” are the most interesting ones; there’s plenty of binary arithmetic coders already and “uABS”, “rABS” or “tABS” do not, at first sight, offer any compelling reasons to switch (that said, there’s some non-obvious advantages that I’ll get to in a later post).
Charles has already posted a good introduction; I recommend you start there. Charles has also spent a lot of time dealing with the table-based coders, and the table-based construction allows some extra degrees of freedom that make it hard to see what’s actually going on. In this post, I’m going to mostly talk about rANS, the range coder equivalent. Charles already describes it up to the point where you try to make it “streaming” (i.e. finite precision); I’m going to continue from there.
Streaming rANS
In Charles’ notation (which I’m going to use because the paper uses both indexed upper-case I’s and indexed lower-case l’s, which would make reading this with the default font a disaster), we have two functions now: The coding function C and the decoding function D defined as


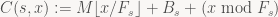
D determines the encoded symbol s by looking at (x mod M) and looking up the corresponding value in our cumulative frequency table (s is the unique s such that 
Okay. If you're working with infinite-precision integers, that's all you need, but that's not exactly suitable for fast (de)compression. We want a way to perform this using finite-precision integers, which means we want to limit the size of x somehow. So what we do is define a "normalized" interval

The [L:bL) thing on the right is the notation I'll be using for a half-open interval of integers). b is the radix of our encoder; b=2 means we're emitting bits at a time, b=256 means we're emitting bytes, and so forth. Okay. We now want to keep x in this range. Too large x don't fit in finite-precision integers, but why not allow small x? The (hand-wavey) intuition is that too small x don't contain enough information; as Charles mentioned, x essentially contains about 
while (!done) {
// Loop invariant: x is normalized.
assert(L <= x && x < b*L);
// Decode a symbol
s, x = D(x);
// Renormalization: While x is too small,
// keep reading more bits (nibbles, bytes, ...)
while (x < L)
x = x*b + readFromStream();
}
Turns out that’s actually our decoding algorithm, period. What we need to do now is figure out how the corresponding encoder looks. As long as we’re only using C and D with big integers, it’s simple; the two are just inverses of each other. Likewise, we want our encoder to be the inverse of our decoder – exactly. That means we have to do the inverse of the operations the decoder does, in the opposite order. Which means our encoder has to look something like this:
while (!done) {
// Inverse renormalization: emit bits/bytes etc.
while (???) {
writeToStream(x % b);
x /= b;
}
// Encode a symbol
x = C(s, x);
// Loop invariant: x is normalized
assert(L <= x && x < b*L);
}
So far, this is purely mechanical. The only question is what happens in the “???” – when exactly do we emit bits? Well, for the encoder and decoder to be inverses of each other, the answer has to be “exactly when the decoder would read them”. Well, the decoder reads bits whenever the normalization variant is violated after decoding a symbol, to make sure it holds for the next iteration of the loop. The encoder, again, needs to do the opposite – we need to proactively emit bits before coding s to make sure that, after we’ve applied C, x will be normalized.
In fact, that’s all we need for a first sketch of renormalization:
while (!done) {
// Keep trying until we succeed
for (;;) {
x_try = C(s, x);
if (L <= x_try && x_try < b*L) { // ok?
x = x_try;
break;
} else {
// Shrink x a bit and try again
writeToStream(x % b);
x /= b;
}
}
x = x_try;
}
Does this work? Well, it might. It depends. We certainly can’t guarantee it from where we’re standing, though. And even if it does, it’s kind of ugly. Can’t we do better? What about the normalization – I’ve just written down the normalization loops, but just because both decoder and encoder maintain the same invariants doesn’t necessarily mean they are in sync. What if at some point of the loop, there are more than two possible normalized configurations – can this happen? Plus there’s some hidden assumptions in here: the encoder, by only ever shrinking x before C, assumes that C always causes x to increase (or at least never causes x to decrease); similarly, the decoder assumes that applying D won’t increase x.
And I’m afraid this is where the proofs begin.
Streaming rANS: the proofs (part 1)
Let’s start with the last question first: does C always increase x? It certainly looks like it might, but there’s floors involved – what if there’s some corner case lurking? Time to check:



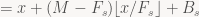

since 



Next up: normalization. Let's tackle the decoder first. First off, is normalization in the decoder unique? That is, if 
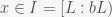


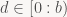
That is, no matter what bit / byte / whatever the decoder would read next (that's 'd'), running through the normalization loop once more would cause x to become too large; there's only one way for x to be normalized. But do we always end up with a normalized x? Again, yes. Suppose that 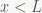


The same kind of argument works for the encoder, which floor-divides by b instead of multiplying b it. The key here is that our normalization interval I has a property the ANS paper calls “b-uniqueness”: it’s of the form 
To elaborate, suppose we have b=2 and some interval where the ratio between lower and upper bound is a tiny bit less than 2: say 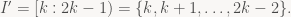


Now let’s try the other direction; again b=2, and this time we make the ratio between upper and lower bound a bit too high: set 

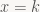

Long story short: if the state intervals involved aren’t b-unique, bad things happen. And on the subject of bad things happening, our encoder tries to find an x such that C(s,x) is inside I by shrinking x – but what if that process doesn't find a suitable x? We need to know a bit more about which values of x lead to C(s,x) being inside I, which leads us to the sets
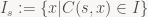
i.e. the set of all x such that encoding 's' puts us into I again. If all these sets turn out to be b-unique intervals, we're good. If not, we're in trouble. Time for a brief example.
Intermission: why b-uniqueness is necessary
Let’s pick L=5, b=2 and M=3. We have just two symbols: ‘a’ has probability 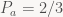
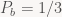
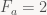

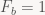




Uh-oh. Neither of these two intervals is b-unique. 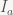
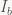
Well, suppose that we’re in state x=7 and want to encode an ‘a’. 7 is not in
Proofs (part 2): a sufficient condition for b-uniqueness
So we just saw that in certain scenarios, rANS can just get stuck. Is there anything we can do to avoid it? Yes: the paper points out that the embarrassing situation we just ran into can’t happen when M (the sum of all symbol frequencies, the denominator in our probability distribution) divides L, our normalization interval lower bound. That is, 


let’s work on that condition:

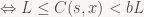

at this point, we can use that
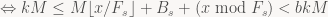

Now, for arbitrary real numbers r and natural numbers n we have that

Using this, we get:

note the term in the outer floor bracket is the sum of an integer and a real value inside 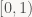

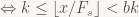
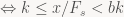


where we applied the floor identities above again and then just multiplied by 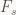
Note that this also gives us a much nicer expression to check for our encoder. In fact, we only need the upper bound (due to b-uniqueness, we know there's no risk of us falling through the lower bound), and we end up with the encoding function
while (!done) {
// Loop invariant: x is normalized
assert(L <= x && x < b*L);
// Renormalize
x_max = (b * (L / M)) * freq[s]; // all but freq[s] constant
while (x >= x_max) {
writeToStream(x % b);
x /= b;
}
// Encode a symbol
// x = C(s, x);
x = freq[s] * (x / M) + (x % M) + base[s];
}
No “???”s left – we have a “streaming” (finite-precision) version of rANS, which is almost like the arithmetic coders you know and love (and in fact quite closely related) except for the bit where you need to encode your data in reverse (and reverse the resulting byte stream).
I put an actual implementation on Github for the curious.
Some conclusions
This is an arithmetic coder, just a weird one. The reverse encoding seems like a total pain at first, and it kind of is, but it comes with a bunch of really non-obvious but amazing advantages that I’ll cover in a later post (or just read the comments in the code). The fact that M (the sum of all frequencies) has to be a multiple of L is a serious limitation, but I don’t (yet?) see any way to work around that while preserving b-uniqueness. So the compromise is to pick M and L to be both powers of 2. This makes the decoder’s division/mod with M fast. The power-of-2 limitation makes rANS really bad for adaptive coding (where you’re constantly updating your stats, and resampling to a power-of-2-sized distribution is expensive), but hey, so is Huffman. As a Huffman replacement, it’s really quite good.
In particular, it supports a divide-free decoder (and actually no per-symbol division in the encoder either, if you have a static table; see my code on Github, RansEncPutSymbol in particular). This is something you can’t (easily) do with existing multi-symbol arithmetic coders, and is a really cool property to have, because it really puts it a lot closer to being a viable Huffman replacement in a lot of places that do care about the speed.
If you look at the decoder, you’ll notice that its entire behavior for a decoding step only depends on the value of x at the beginning: figure out the symbol from the low-order bits of x, go to a new state, read some bits until we’re normalized again. This is where the table-based versions (tANS etc.) come into play: you can just tabulate their behavior! To make this work, you want to keep b and L relatively small. Then you just make a table of what happens in every possible state.
Interestingly, because these tables really do tabulate the behavior of a “proper” arithmetic coder, they’re compatible: if you have two table-baked distributions with use that same values of b and L (i.e. the same interval I), you can switch between them freely; the states mean the same in both of them. It’s not at all obvious that it’s even possible for a table-based encoder to have this property, so it’s even cooler that it comes with no onerous requirements on the distribution!
That said, as interesting as the table-based schemes are, I think the non-table-based variant (rANS) is actually more widely useful. Having small tables severely limits your probability resolution (and range precision), and big tables are somewhat dubious: adds, integer multiplies and bit operations are fine. We can do these quickly. More compute power is a safe thing to bet on right now (memory access is not). (I do have some data points on what you can do on current HW, but I’ll get there in a later post.)
As said, rANS has a bunch of really cool, unusual properties, some of which I’d never have expected to see in any practical entropy coder, with cool consequences. I’ll put that in a separate post, though – this one is long (and technical) enough already. Until then!

When considering the headers, the compression is not better than huffman (verified). The compression speed is much worse and the decompression speed can’t be better than huffman.
Whether *ANS (or any arithmetic coder for that matter) compresses better than Huffman depends on the symbol distribution. Mostly flat distributions don’t see much change, but the difference can be huge, for skewed distributions in particular (try a 3-symbol alphabet where p(a)=0.9, p(b)=0.05, p(c)=0.05). General lossless compressors don’t see that kind of data much, but the backend compressors in e.g. lossy audio/image/video codecs often do.
You’re also presuming that the tables (or sufficient data to reconstruct them) are sent with the file. Again, that’s not always the case, with an example being audio/image/video codecs where Huffman tables (when used) are usually part of the standard.
Compression/decompression speed: again, rANS is an arithmetic coder, with some extra constraints but usually faster coding/decoding (assuming a static table). A typical rANS implementation is slower than a typical Huffman coder/decoder, but about ~2x faster than a typical arithmetic coder with comparable compression performance (again, assuming static tables; once you try adaptive multi-symbol coding, that advantage disappears). That puts it at a pretty good spot in terms of the compression ratio/speed trade-off curve. If you need better-than-Huffman but aren’t willing to take the >=4x decode time hit that switching to an arithmetic coder would mean, rANS is a very useful option to have.
Furthermore, it has some other useful properties that other coders don’t have and that I’ll be discussing in an upcoming post.
Then there’s the fully table-based variants, tANS/FSE. Again, different point on the trade-off curve. They’re faster but somewhat sloppier, and they require relatively large tables to achieve good rates. That’s the variants where the stupid “faster than Huffman” (which is wrong) claims come from. I think Jarek’s totally over-selling them; the non-table-driven coders are much more interesting if you ask me. (And they can be very fast, much faster than my sample implementation, which again I will get to).
Could you clarify the “reversing” aspect of these algorithms? Did I undestand correctly that compression followed by decompression will always reproduce the original data stream in reverse order?
It’s essentially a stack – last in, first out (this is the direct result of the construction based on mutually inverse coding/decoding functions C and D). So the last symbol encoded will be the first symbol returned by the decoder. Likewise, the decoder reads the encoded bitstream in reverse order; the last bits (bytes, …) written by the encoder will be consumed first by the decoder.
In the example code on Github, encoding proceeds backwards from the end of the file towards the beginning, and the resulting bitstream is also written in reverse. Since I reverse data before encoding, then reverse the results, the decoder just proceeds forward in both the compressed and decompressed data streams; that is, the burden of dealing with the reversals is left on the encoder side.
I was asking because this property is very interesting for streams that should be decoded revserse by their nature. For example, in the “reverse mode” of automatic differentiation, which is e.g. used for efficient computation of the gradient of a model function, a huge stack is generated that will then be processed backwards. Since that whole operation is memory-bound, trading some cpu power to reduce memory usage (e.g. by compression) is a good thing to do.
The obvious solution is to compress the stack blockwise, and to uncompress the blocks in reverse order. Or, to use an old trick from the 60s that allows you to make any prefix-code stream bidirectionally decodable with just a tiny overhead, but assumes that the codes retain their meaning throughout the whole process. The new *ANS algorithms, however, may provide a direct approach to that problem.
The remaining problem is, however, that Huffman or AC is usually the second step of compression, prepended by some Lempel-Ziv variant. And speaking of application in automatic differentiation, Lempel-Ziv does the horse work of getting the size down. So even with reverse-decodable AC, you then still have to problem to reserve-decode Lempel-Ziv.
So one more question:
Are you aware of any way to make some Lempel-Ziv variant reverse-decodable, too, so the combination AC+LZ becomes reverse-decodable? (I don’t care about the exact LZ variant, anything from old-fashioned LZ77 to modern LZMA is worth a try)
LZ77 doesn’t really care about direction. What matters is that any string matches the encoder sends must only reference data that the decoder has already seen at the point where the match occurs in the bit stream.
Of course what that means for an encoder operating in a stack fashion is that all acceptable targets for string matches are *after* (not before) the current symbol. Which means that for say a maximum match offset of 64k, the encoder must have 64k of lookahead. You see where this is going.
A similar problem exists with any kind of adaptive model. Any model adaption you do must be causal from the decoder’s perspective – which means that, from the encoder’s point of view, it happens backwards. So the encoder ends up having to do first a forward pass to do the probability modeling and then a backwards pass to actually write the bit stream.
The sweet spot for ANS is as a replacement for static model coders; you need to buffer up a bunch of data to gather stats anyway, and once you have that buffer, whether you loop forwards or backwards over it to produce the bitstream doesn’t make much of a difference.
But for anything adaptive or on-line, this buffering is something you wouldn’t do with an ordinary arithmetic coder. This should factor into your evaluation of whether ANS is suitable for your purposes or not.
regarding https://github.com/rygorous/ryg_rans
you can put “sym->freq”, “(x & mask) – start” in “cum2sym ” table, get all this data by one memory read. You can pack this in uint64, or in uint32 (pack just “(x & mask) – start”). This will give about 10%-20% speed gain.
And better to use assembler. c++ is unpredictable.
This code was intended to show the algorithm clearly, not to be as fast as possible. I’m certainly not going to post assembly code which would limit its usefulness to people writing code for x86/x64. (I do a lot of work for ARM/PowerPC targets, for example)
I’ve been experimenting with different ways to do the symbol lookup; large lookup tables were not the sweet spot in my tests, certainly not for the m=2^14 or higher that I’m using (even the cum2sym table with 1 byte/entry is on the large side in terms of the fraction of L1 cache that it occupies).
Another problem with large tables is the time required to build them. E.g. if you switch models every 32k-64k or so (think Deflate), you will spend more time populating a 128k table than you later gain from using it.
That said, if you’re only using smaller m (say around m=2^12), having 4-byte table entries is 16k which is reasonable on most targets. Just make sure to stay well within the L1 cache or you’ll fall off a cliff.
@enotus, any sources to tests all your suggestions?
2sib
http://pastebin.com/D7FpyXv3
i also found simple way to deal with sum(counters)!=2^k, just add dummy symbol to dictionary (with count=1) and encode it when detected out of sync. If stateMax >> sum(counters), this adds little loss of compression.
Choosing M=L, b=2 degenerate case, there is no longer multiplication/division needed – at cost of slightly worse compression rate (comparable to Huffman) – maybe it could be useful for some ultrafast e.g. texture compression …
discussion: http://encode.ru/threads/2035-tANS-rANS-fusion-further-simplification-at-cost-of-accuracy