What happens when iterating filters?
Casey Muratori posted on his blog about half-pixel interpolation filters this week, where he ends up focusing on a particular criterion: whether the filter in question is stable under repeated application or not.
There are many things about filters that are more an art than a science, especially where perceptual factors are concerned, but this particular question is both free of tricky perceptual evaluations and firmly in the realm of things we have excellent theory for, albeit one that will require me to start with a linear algebra infodump. So let’s get into it!
Analyzing iterated linear maps
Take any vector space V over some field 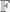

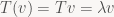
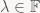
Now when we’re iterating the map T multiple times, eigenvectors of T behave in a very simple way under the iterated map: we know that applying T to v gives back a scaled version of v, and then linearity of T allows us to conclude that:
and more generally 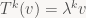
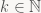
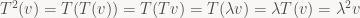
The best possible case is that we find lots of eigenvectors – enough to fully characterize the map purely by what it does on its eigenvectors. For example, if V is a finite-dimensional vector space with 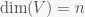
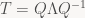
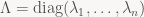
That is, in the right basis (made of eigenvectors), T is just a diagonal matrix, which is to say, a (non-uniform) scale. This makes analysis of repeated applications of T easy, since:
and in general
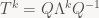
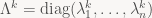
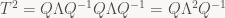
Not every matrix can be written that way; ones that can are called diagonalizable. But there is a very important class of transforms (and now we allow infinite-dimensional spaces again) that is guaranteed to be diagonalizable: so called self-adjoint transforms. In the finite-dimensional real case, these correspond to symmetric matrices (matrices A such that 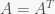
As a small aside, if you’ve ever wondered why iterative solvers for linear systems usually require symmetric (or, in the complex case, Hermitian) matrices: this is why. If a matrix is symmetric, it it diagonalizable, which allows us to build an iterative process to solve linear equations that we can analyze easily and know will converge (if we do it right). It’s not that we can’t possibly do anything iterative on non-symmetric linear systems; it just becomes a lot trickier to make any guarantees, especially if we allow arbitrary matrices. (Which could be quite pathological.)
Anyway, that’s a bit of background on eigendecompositions of linear maps. But what does any of this have to do with filtering?
Enter convolution
Convolution itself is a bilinear map, meaning it’s linear in both arguments. That means that if we fix either of the arguments, we get a linear map. Suppose we have a FIR filter f given by its coefficients 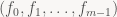
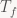
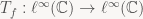

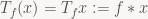
If this is all a bit dense on notation for you, all I’m doing here is holding one of the two arguments to the convolution operator constant, and trying to at least specify what set our map is working on (in this case, bounded sequences of real numbers).
And now we’re just about ready for the punchline: we now have a linear map from a set to itself, although in this case we’re dealing with infinite sequences, not finite ones. Luckily the notions of eigenvectors (eigensequences in this case) and eigenvalues generalize just fine. What’s even better is that for all discrete convolutions, we get a full complement of eigensequences, and we know exactly what they are. Namely, define the family of sequences 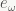
![\displaystyle e_\omega[n] = \exp(i \omega n) = \cos(\omega n) + i \sin(\omega n)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+e_%5Comega%5Bn%5D+%3D+%5Cexp%28i+%5Comega+n%29+%3D+%5Ccos%28%5Comega+n%29+%2B+i+%5Csin%28%5Comega+n%29&bg=f9f7f5&fg=444444&s=0&c=20201002)
That’s a cosine wave with frequency ω in the real part and the corresponding sine wave in the imaginary part, if you are so inclined, although I much prefer to stick with the complex exponentials, especially when doing algebra (it makes things easier). Anyway, if we apply our FIR filter f to that signal, we get (this is just expanding out the definition of discrete convolution for our filter and input signal, using the convention that unqualified summation is over all values of k where the sum is well-defined)
![\displaystyle (T_f e_\omega)[n] = \sum_k f_k \exp(i \omega (n-k))](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%28T_f+e_%5Comega%29%5Bn%5D+%3D+%5Csum_k+f_k+%5Cexp%28i+%5Comega+%28n-k%29%29&bg=f9f7f5&fg=444444&s=0&c=20201002)
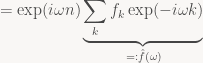

There’s very little that happens here. The first line is just expanding the definition; then in the second line we use the properties of the exponential function (and the linearity of sums) to pull out the constant factor of 
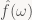
Also note that the formula for the eigenvalue isn’t particularly scary either in our case, since we’re dealing with a FIR filter f, meaning it’s a regular finite sum:
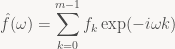
Oh, and there’s one more minor detail I’ve neglected to mention so far: that’s just the discrete-time Fourier transform (DTFT, not to be confused with the DFT, although they’re related) of f. Yup, we started out with a digital FIR filter, asked what happens when we iterate it a bunch, did a brief detour into linear algebra, and ended up in Fourier theory.
Long story short, if you want to know whether a linear digital filter is stable under repeated application, you want to look at its eigenvalues, which in turn are just given by its frequency response. In particular, for any given frequency ω, we have exactly three options:
. In this case, the amplitude at that frequency is preserved exactly under repeated application.
. If the filter dampens a given frequency, no matter how little, then the amplitude of the signal at that frequency will eventually be driven to zero. This is stable but causes the signal to degrade. Typical interpolation filters tend to do this for the higher frequencies, which is why signals tend to lose such frequencies (in visual terms, get blurrier) over time.
. If a filter amplifies any frequency by more than 1, even by just a tiny bit, then any signal containing a nonzero amount of that frequency will eventually blow up.
The proof for all three cases is simply observing that k-fold application of the filter f to the signal 
Therefore, all you need to know about the stability of a given filter under repeated application is contained in its Fourier transform. I’ll try to do another post soon that shows the Fourier transforms of the filters Casey mentioned (or their magnitude response anyway, which is what we care about) and touches on other aspects such as the effect of rounding and quantization, but we’re at a good stopping point right now, so I’ll end this post here.

Why do we have reason to believe that convolution in particular is a diagonalizable or self-adjoint linear map?
In this particular case, the reason to believe that convolution with a fixed sequence is diagonalizable is because we have a full complement of eigensequences. That is the definition of diagonalizability!
Discrete convolution is not generally self-adjoint, and I do not state anywhere that it is. I just mentioned self-adjoint operators because they’re the most important class of diagonalizable transforms by far.
Ok, thanks. It’s helpful to see the explicit link between eigenvalue/eigenvector analysis and Fourier transforms, looking forward to part 2.
Thank you for these posts, they serve as real good references I can point people to. On a related note, I find that a lot of people would benefit from reading Thevanaz/ Unser’s work on filtering – both the research and the tutorials on spline-based filtering, constructing compact IIR filters for resampling, the whole shebang. I think the research has moved onto other topics, but the older publications (and even some of the sample C code) are very nice. The tutorials at http://bigwww.epfl.ch/tutorials/index.html/?k=tutorials are a great starting point.